



如何利用BI工具進行業務數據分析?
FineBI是一款自助式分析工具,在功能上將數據準備工作與業務數據分析工作分開。提倡IT部門準備好數據,提供給業務部門自助分析,讓各個部門做各自最擅長的事情。解放IT部門壓力的同時,也能讓業務部門能夠根據自己的業務需求,快速獲得即席分析結果。
在這里以一個醫藥行業對某地區某藥品的庫存周轉做調整的分析過程為例,講解FineBI的使用場景,看下FineBI在各個部門中所發揮的作用。
視頻加載中...
在開始之前,我們需要考慮業務部門可能存在的各種復雜操作,以及實時性需求,數據量的大小等。
假設數據庫的查詢性能并不是特別好,而同時業務部門需要快速的展示分析,那此時就可以考慮將數據放到專門為查詢分析提供支撐的引擎FineIndex中做對接。
假設數據庫性能可以支撐,或者業務的實時性要求很高,那就可以使用FineDirect引擎做對接。
關于FineDirect和FineIndex
FineIndex提供基于索引的高效計算引擎,對數據進行抽取預處理,高壓縮比,通過索引支撐前端快速數據分析。
支撐前端分析:FineIndex對抽取的數據進行預處理,支撐前端數據分析和展現的速度。
底層數據處理:抽取的數據存儲在磁盤,采用列式存儲,位圖索引等大數據處理技術,有效應對企業億級數據量。
FineDirect是FineBI推出的大數據直連引擎功能模塊,用于解決處理超大數據量和超快的實時數據分析需求。
通過FineDirect直連引擎,企業可以直接對接現有的數據源,無論是傳統的關系型數據庫(Oracle,Sqlserver),還是日益成熟的Hadoop生態圈,Mpp構架的解決方案,都可以直接進行自助取數分析,可以不再經過FineBI的多維數據庫(FineIndex)建模,實現更敏捷的、更及時的決策分析。
其中FineIndex的預建模與預先建立索引都可讓數據的展示達到秒出的效果。
而FineDirect的優化SQL與參數等功能,在體現數據庫本身性能優勢的同時,智能緩存還可協助緩解數據庫壓力,提升查詢速度。

數據準備步驟:
1、我們這里選擇將數據抽取到FineIndex中,選擇相應的表添加過來。——對應操作:添加表
2、在這里,可以選擇不同數據庫的表,這些表之間是可以做主子表之間的關聯關系,從而實現多源數據統一平臺的整合。——對應操作:增加表之間的關聯關系
3、假設有的表要做一些預處理,可以使用內置的ETL功能,實現簡單的ETL操作。——對應操作:可視化ETL
4、那這里是在我們處理好了表關系之后,就可以將這些數據提供給業務部門使用了。——對應操作:IT準備數據,業務部門分析數據
5、假設此時我是業務人員,想要看到各地區醫藥客戶的銷量、周轉等情況。——對應操作:在前端拖拽圖表和表格,建立可視化分析

具體分析操作:
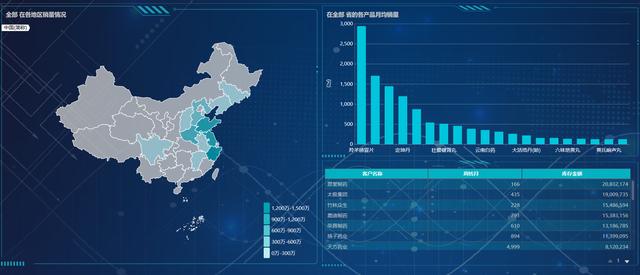
首先,我發現山東省的銷量很高,點擊之后有自然的聯動效果,發現對應**藥品的銷量是最高的。
那我就想看各個客戶分銷的情況,是否有必要調整各分銷客戶的藥品庫存。
發現**的庫存金額最多,周轉月少,而**的庫存金額少,周轉月多。因此可以將X的Y藥品 周轉到**賣掉。
這樣,在同一地區對貨品做周轉,降低了運貨成本,同時這樣的調整,也可以提高Y藥品的銷量。
最后,想將這個分析的內容給領導查看,讓領導做決策。就可以將樣式做相應調整,調整之后就可以給領導查看這個分析了。
這樣,就在BI中完成了整個的數據分析過程。
下一篇: 如何進入大數據領域,學習路線是什么?
